So as part of my job I'm picking up some work with BizTalk 2009 server. I have used SSIS and have been told by many people that Biztalk 2009 is the "big brother" to SSIS.
This is my first Biztalk application and I'm blogging this while I'm creating it. I've received no training, and saw the Administration Console for the first time about 20 minutes ago. To quote Jeremy Clarkson; "How hard can it be?"
To start with I've right-clicked the "Applications" group in the Admin Console and selected "New";
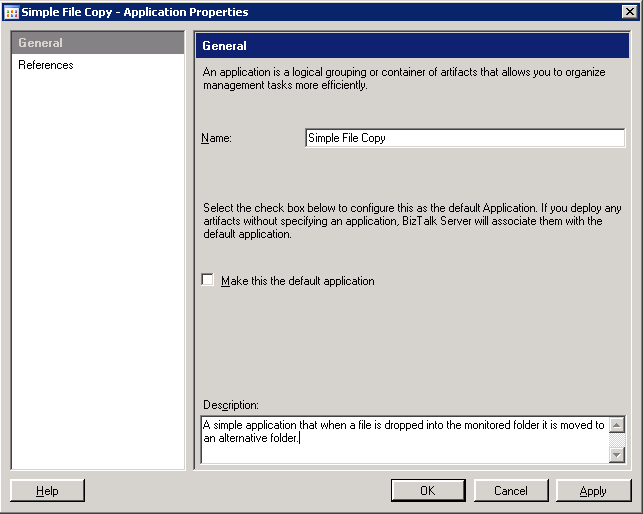 |
| Biztalk 2009: New Application Properties |
I've entered the name "Simple File Copy" and a brief description. Once the new application has been created if you expand it in Navigation view you can see;
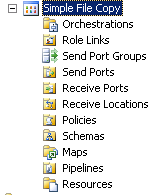 |
| Biztalk 2009: Expanded Navigation View |
This is going to be a simple application; it isn't going to involve Orchestrations, Policies, Schemas, etc - I'm fact it's only going to involve creating a "Receive Port" for the folder we want to drop files into and a "Send Port" for the folder we want to write the files out to.
So the first thing I'm going to do is to create a "Receive Port", right-clicking on the "Receive Ports" item in the Navigation View and selecting "New" and then "One-way Receive Port...";
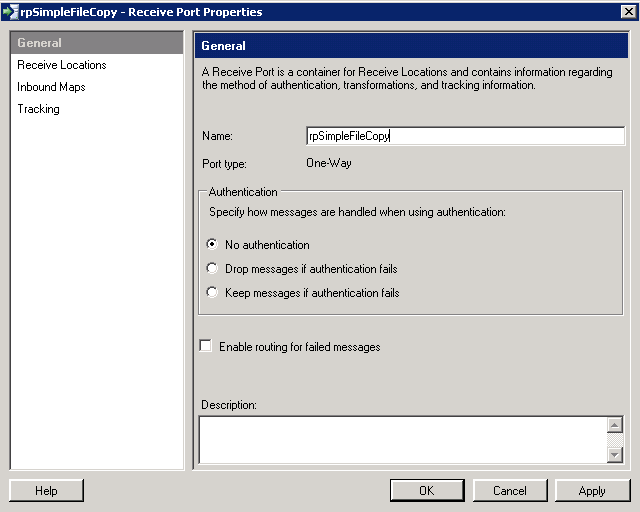 |
| Biztalk 2009: Receive Port Properties |
I've named this Receive Port "rpSimpleFileCopy", I'm not going to use authentication as it's just going to be accessing a folder on the local machine. Next the "Receive Locations" section on the left;
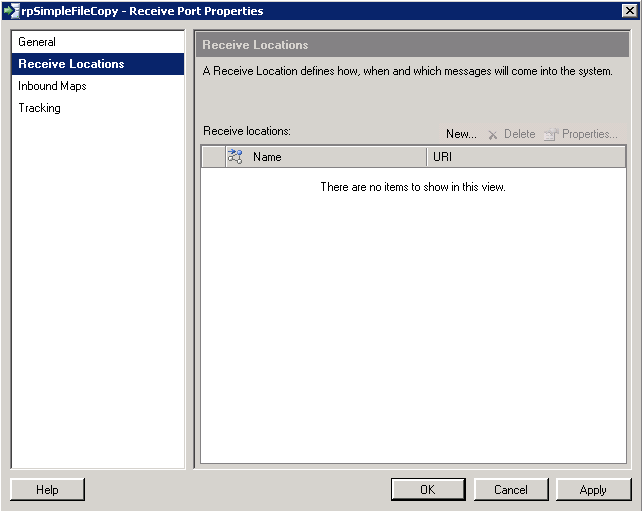 |
| Biztalk 2009: Receive Locations |
Click on the "New ..." button;
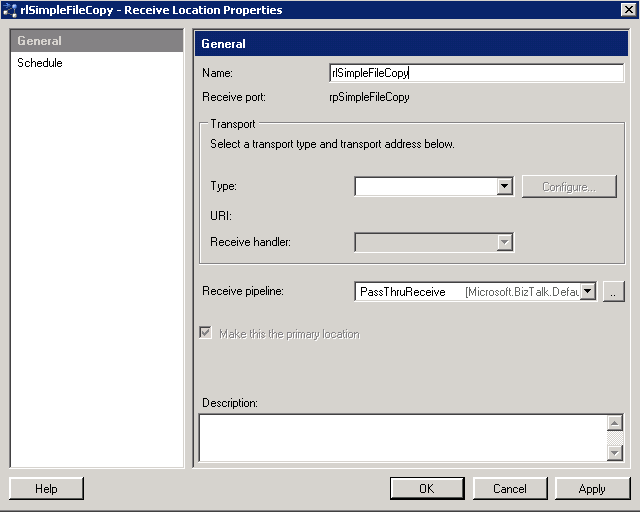 |
| Biztalk 2009: Receive Location Properties |
Now I'm going to setup a simple file location for the input, select "FILE" in the type drop down and then click on "Configure" to set the details;
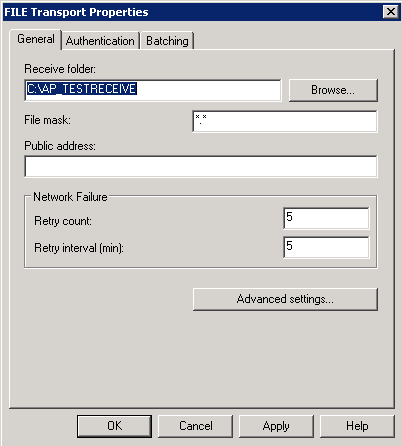 |
| Biztalk 2009: FILE Transport Properties |
As you can see I've just browsed to a folder I created earlier (AP_TESTRECEIVE) and selected it, I've also changed the "File mask" from *.xml to *.* (as I'm interested in everything).
Click "OK" (I don't want to do anything with Authentication and Batching - just accepting the defaults)
Click "OK" - we're back on the Receive Location Properties dialog and I'm happy to accept the default schedule.
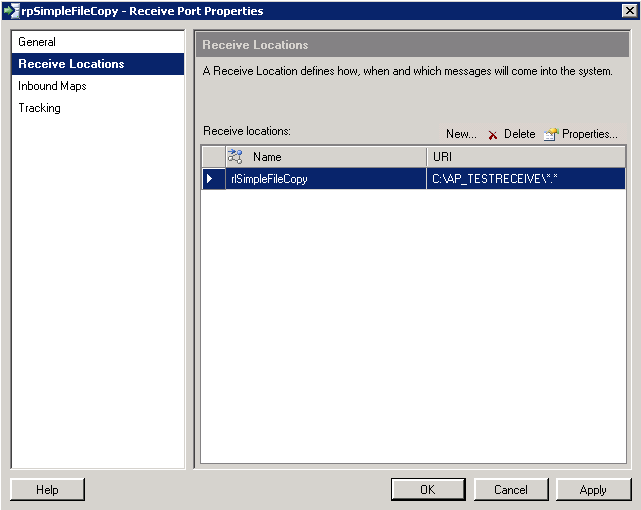 |
| Biztalk 2009: Receive Port Properties - Receive Locations |
Click "OK" to save the Receive Port. This took a few seconds to save the settings.
We're now back at looking in the Admin console, if you click on the "Applications" node you'll see the list of currently applications with our new one currently showing as "Stopped";
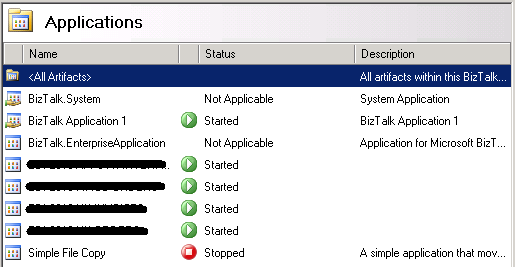 |
| Biztalk 2009: Installed Applications in the Admin Console |
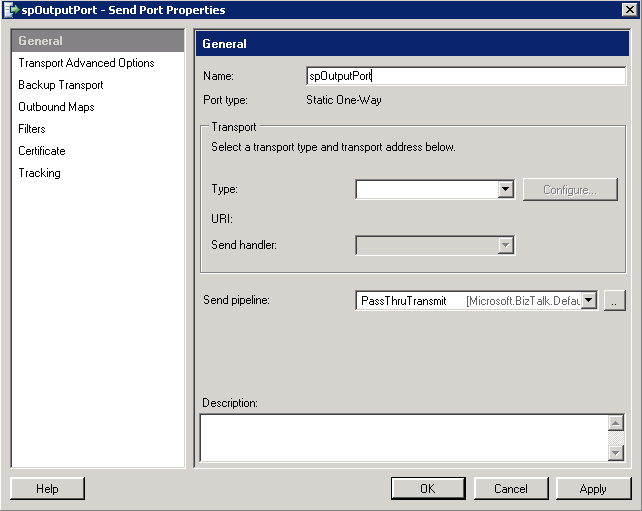
Click on "Send Ports" in the navigation view and select "New" and then select "Static One-way Send Port ...";
 |
| Biztalk 2009: Send Port Properties |
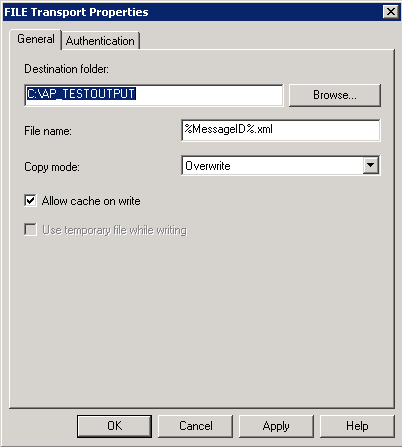
I've changed the name to "spOutputPort", now select "FILE" and then click "Configure";
 |
| Biztalk 2009: FILE Transport Properties |
I've set the output folder to a folder on the local machine and left everything else as default.
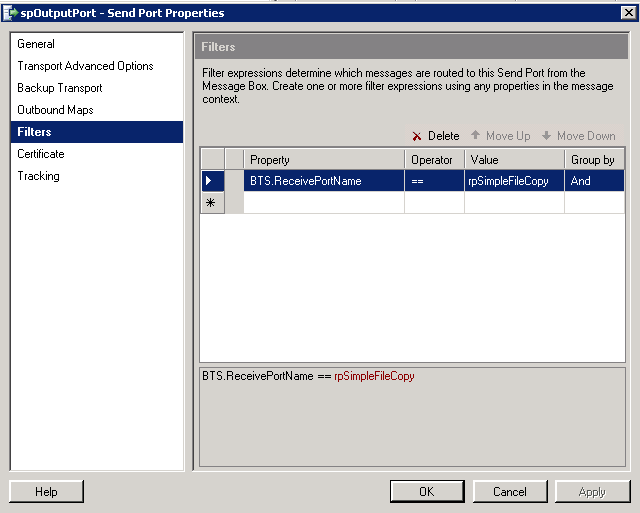
Click "OK", we're now mach to the main "Send Port Properties" dialog, select "Filters";
 |
| Biztalk 2009: Send Port Properties - Filters |
Now what we're going to do is tie our Send Port to our existing Receive Port. To do this just select "BTS.ReceivePortName", "==" as the operator, and enter "rpSimpleFileCopy" as the value.
Everything else we're not going to change - click "OK".
Now that's it ... What we need to do now is to activate the Receive and Send ports we've created and the Application will start working.
Click on "Receive Locations";
 |
| Biztalk 2009: Receive Locations (Disabled) |
Right-click the single line and select "Enable";
 |
| Biztalk 2009: Receive Locations (Enabled) |
Now click on "Send Ports" in the Navigation View;
 |
| Biztalk 2009: Send Ports (Disabled) |
Right-click the single line and select "Start";
 |
| Biztalk 2009: Send Ports (Enabled) |
And that's it, now you just drop a file into the C:\AP_TESTRECEIVE and a few seconds later the file will disappear and if you check the C:\AP_TESTOUTPUT folder an XML file - named with a GUID - will have appeared.
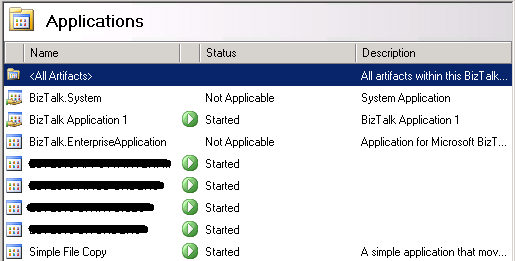
As a final check here is a list of the Applications on the server;
 |
| Biztalk 2009: Applications - Simple File Copy (Started) |
Getting to this stage took about an hour, maybe two.
NOTE: Because we changed the file input to "*.*" any file dropped will be transferred, I've tried both text and XML files and everything seems to work fine.