This blog post describes a remedy for the issue which prevents Report Builder 3 from working with a Report in SharePoint integrated mode that has been migrated to SharePoint from a different server.
At the moment Microsoft has no solution for this issue (other that "don't use Report Builder 3).
NOTE: The exact problem that this blog post is showing you how to fix is detailed in another post
here.
Background/ SetupThe first step in fixing this problem is gathering all the information. Each of your Reports will have embedded into it both the previous server URL and the location it was using on that server for it's Data Set. In this example we will assume the following;
The original server used the structure;
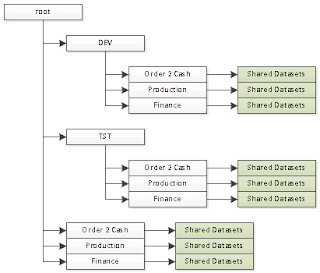 |
| SSRS: Non-Sharepoint Integrated Mode Folder Structure |
With the root folder being treated as "live" and the DEV and TST folders being hidden. The only location for data sets is in the "Shared Datasets" folders (highlighted in green).
This gives us the following list of "possible" sources for Data sets;
- /DEV/Order 2 Cash/Shared Datasets
- /DEV/Production/Shared Datasets
- /DEV/Finance/Shared Datasets
- /TST/Order 2 Cash/Shared Datasets
- /TST/Production/Shared Datasets
- /TST/Finance/Shared Datasets
- /Order 2 Cash/Shared Datasets
- /Production/Shared Datasets
- /Finance/Shared Datasets
Each of these will need to be mapped to the "new" folder on the SharePoint integrated mode server. For the purposes of this example (and to assume maximum change) I'm going to assume the structure of the new server is;
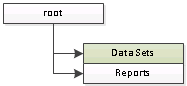 |
| SharePoint Integrated Mode Structure |
Assuming you're following Microsoft "guidance" (using properties rather than folders) it's quite possible you could end up with something like this.
One other difference between non-integrated mode and integrated mode is that the Data Sets now have .rsd as a suffix (which makes sense - but is annoying).
An the final difference is in the server name itself (well assuming you did a migration rather than an upgrade to the server!). In our example I'm going to assume the SharePoint server is called "ssrsintegrated" and the other server is called "ssrs".
And that's it - a complete list of all the changes we need to make.
Configuring The ApplicationThe first step is to download and open the application (it's open-source and you can find the details of how to get hold of it on another blog post
TS&R: Replacing Text in Multiple Files).
The
Search Folder needs to be set to point to the SharePoint servers' published folder for the "Reports "document library;
\\ssrsintegrated\DavWWWRoot\Reports\
The
File Extensions we are interested in need to be restricted to SSRS Reports;
|*.rdl|
The vertical lines either side will be added when you enter "*.rdl" into the entry box;
Next is the
Replace Strings entry box. Copy/Paste the following lines;
/DEV/Finance/Shared Datasets/|/Data Sets/
/DEV/Production/Shared Datasets/|/Data Sets/
/DEV/Order 2 Cash/Shared Datasets/|/Data Sets/
/TST/Finance/Shared Datasets/|/Data Sets/
/TST/Production/Shared Datasets/|/Data Sets/
/TST/Order 2 Cash/Shared Datasets/|/Data Sets/
/Finance/Shared Datasets/|/Data Sets/
/Production/Shared Datasets/|/Data Sets/
/Order 2 Cash/Shared Datasets/|/Data Sets/
http://ssrs/ReportServer|http://ssrsintegrated
http://ssrs/reportserver|http://ssrsintegrated
|.rsd
.rsd.rsd|.rsd
NOTE: The first 9 lines are just mapping old data set directories to the new one, the next two lines map the old URL's to the new one (you'll need to add additional lines if your developers capitalisation is not consistent - thankfully ours just settled on two versions!), the next line adds the .rsd to the Data Set reference and the final line removes duplicates if it was already there!
Finally an
Output Folder needs to be selected (i.e. C:\TEMP\Report Output\).
Click "Execute" and the changes will be made and updated files will be placed in the C:\TEMP\Report Output\ directory - reports which are not changed will not be included in the new directory (so you could repeatedly run this process as you migrate new reports and only change the new reports).
SummaryNot the easiest method I know but at least it works and if you have 2/300 files it's a lot quicker than manual updates. It's completely ludicrous that Microsoft haven't patched this problem - it does make "Report Builder 3" a completely useless product in some specific circumstances and "just use BIDS" is not really acceptable unless they're going to scrap Report Builder 3!







